- Scalable implementation for MPI I/O atomicity
- Coherent cache access for collective MPI I/O
- Client-side file caching sub-system at MPI I/O level
Scalable implementation for MPI I/O atomicity
I/O atomicity is referred to as the outcome of the overlapped regions, both in the file and process's memory, from a concurrent overlapping I/O operation. Atomic I/O indicates that all the overlaps between two or more processes come from one of the processes only. While the POSIX standard demands the atomicity for individual read/write calls, the MPI semantics require the atomicity in the granularity of MPI I/O call. Since MPI allows a process to access multiple non-contiguous file regions in a single I/O call, guarantee of atomic I/O in each contiguous region is not sufficient to achieve the results required by the MPI standard. Figure 1 shows an example of a concurrent write operation from two MPI processes in both atomic and non-atomic modes. A two-dimensional array is partitioned between two processes with a few columns overlapped. To gain exclusive access to a file region, most of the file systems provide byte-range file locking, which can be used to achieve the desired I/O atomicity. However, file locking can potentially serialize the I/O parallelism.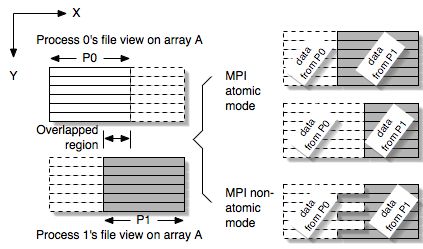
Figure
1. A 2D column-wise partitioning with overlaps between 2 processes. In
MPI atomic mode, data in the overlapped regions can only come from
either P0 or P1. Otherwise, the result is undefined, for example,
interleaved.
We propose two scalable methods for MPI atomicity: graph coloring and process-rank ordering. These two methods allow the MPI processes to negotiate with each other for the access orders when overlaps occur. For graph-coloring method, wefirst divide the processes into k groups (colors) in which no two processes in a group overlap, then the concurrent write is carried out in k steps. This graph-coloring approach can maintain a degree of I/O parallelism if k < P, the number of processes. For process-rank ordering method, we let the highest ranked processes win whenever an overlap
occurs between two or more processes. As a result, the lower ranking processes modify their requests by subtracting the overlaps. This approach can fulfill the atomicity requirement, because data resulting in any overlap of two or more processes will come from the process with the highest rank.
As described in the previous section, the atomicity semantics do not specify exactly which process's data shall appear in the overlap. As long as the data of the overlap all come from the same process, it is considered an atomic I/O.
We propose a scalable approach, called persistent file domain (PDF), that reuses the file access information from the preceding MPI I/O operations to guide the subsequent I/O to the processes that hold the most up-to-date cache. In ROMIO, a popular MPI implementation developed at Argonne National Laboratories (ANL), the life of the file domains only spans a single MPI collective I/O call. Our persistent file domain approach, on the contrary, preserves the file domains for the subsequent I/O operations to avoid accessing to obsolete cache data. We further analyze three domain assignment strategies for the PFD method. User specified stripe size provides users an option to supply a customized stripe size through an MPI_Info object to the PFD. The PFD uses it to statically assign the file domains by cyclically striping the file across all the processes that open the file collectively. File view based assignment automatically calculates a new PFD assignment each time a new MPI file view is set. Once a file is opened and the file views are set, the stripe unit size is computed by dividing the aggregate access region of the first collective I/O by the number of the processes. Aggregate access region based assignment re-calculates the PFD when the size of aggregate access region is changed. The size of aggregate access region will change in two situations: 1) the file view is changed; and 2) the argument of I/O buffer derived data type in the collective I/O call is changed.
We design a client-side file caching sub-system that coordinates the MPI application processes to manage cache data and achieve cache coherence without involving the I/O servers. We consider all processes that run the same application as a single client and file caching is performed and managed by the clients only. This idea is illustrated in Figure 2. We first logically divide a file into blocks of the same size in which each block represents an indivisible page that can be cached in a process's local memory. Cache metadata describing the caching status of these file blocks is distributed in a round-robin fashion among the processes that together open the file. Since cache data and metadata are distributed among processes, each process must be able to response to remote requests for accessing to data stored locally. For MPI collective I/O where all processes must be synchronized, fulfilling remote requests can be achieved by first making each request known to all processes and, then, using inter-process communication to deliver data to the requesting processes. On the contrary, MPI independent I/O is asynchronous which makes it difficult for one process to explicitly receive remote requests. Therefore, our design needs a mechanism to allow a process to access to remote memory without interrupting the execution of the remote processes. To demonstrate this idea, we proposed two implementations: using a client I/O thread and using MPI remote memory access utility.
We propose two scalable methods for MPI atomicity: graph coloring and process-rank ordering. These two methods allow the MPI processes to negotiate with each other for the access orders when overlaps occur. For graph-coloring method, wefirst divide the processes into k groups (colors) in which no two processes in a group overlap, then the concurrent write is carried out in k steps. This graph-coloring approach can maintain a degree of I/O parallelism if k < P, the number of processes. For process-rank ordering method, we let the highest ranked processes win whenever an overlap
occurs between two or more processes. As a result, the lower ranking processes modify their requests by subtracting the overlaps. This approach can fulfill the atomicity requirement, because data resulting in any overlap of two or more processes will come from the process with the highest rank.
As described in the previous section, the atomicity semantics do not specify exactly which process's data shall appear in the overlap. As long as the data of the overlap all come from the same process, it is considered an atomic I/O.
Coherent cache access for collective MPI I/O
In this task, we consider the I/O patterns with the overlaps across a sequence of collective MPI I/O operations. This subsequent overlapping I/O happens when the same data accessed by an earlier MPI I/O operation is accessed later by another I/O operation. On parallel machines that perform client-side file caching, the subsequent overlapping I/O can lead to the {\it cache coherence} problem. Incoherent cache occurs when multiple copies of the same data are stored at different clients and a change to one copy does not propagate to others in time, leaving the cached data in an incoherent state. Traditionally, the file consistency problem can be solved by using byte-range file locking, because once a file region is locked, any read/write operations will go directly to the I/O servers. However, this approach can significantly increase the communication overhead between clients and servers.We propose a scalable approach, called persistent file domain (PDF), that reuses the file access information from the preceding MPI I/O operations to guide the subsequent I/O to the processes that hold the most up-to-date cache. In ROMIO, a popular MPI implementation developed at Argonne National Laboratories (ANL), the life of the file domains only spans a single MPI collective I/O call. Our persistent file domain approach, on the contrary, preserves the file domains for the subsequent I/O operations to avoid accessing to obsolete cache data. We further analyze three domain assignment strategies for the PFD method. User specified stripe size provides users an option to supply a customized stripe size through an MPI_Info object to the PFD. The PFD uses it to statically assign the file domains by cyclically striping the file across all the processes that open the file collectively. File view based assignment automatically calculates a new PFD assignment each time a new MPI file view is set. Once a file is opened and the file views are set, the stripe unit size is computed by dividing the aggregate access region of the first collective I/O by the number of the processes. Aggregate access region based assignment re-calculates the PFD when the size of aggregate access region is changed. The size of aggregate access region will change in two situations: 1) the file view is changed; and 2) the argument of I/O buffer derived data type in the collective I/O call is changed.
Client-side file caching sub-system at MPI I/O level
Parallel file subsystems in today's high-performance computers adopt many I/O optimization strategies that were designed for distributed systems. These strategies, for instance client-side file caching, treat each I/O request process independently, due to the consideration that clients are unlikely related with each other in a distributed environment. However, it is inadequate to apply such strategies directly in the high-performance computers where most of the I/O requests come from the processes that work on the same parallel applications. We believe that client-side caching could perform more effectively if the caching sub-system is aware of the process scope of an application and regards all the application processes as a single client.We design a client-side file caching sub-system that coordinates the MPI application processes to manage cache data and achieve cache coherence without involving the I/O servers. We consider all processes that run the same application as a single client and file caching is performed and managed by the clients only. This idea is illustrated in Figure 2. We first logically divide a file into blocks of the same size in which each block represents an indivisible page that can be cached in a process's local memory. Cache metadata describing the caching status of these file blocks is distributed in a round-robin fashion among the processes that together open the file. Since cache data and metadata are distributed among processes, each process must be able to response to remote requests for accessing to data stored locally. For MPI collective I/O where all processes must be synchronized, fulfilling remote requests can be achieved by first making each request known to all processes and, then, using inter-process communication to deliver data to the requesting processes. On the contrary, MPI independent I/O is asynchronous which makes it difficult for one process to explicitly receive remote requests. Therefore, our design needs a mechanism to allow a process to access to remote memory without interrupting the execution of the remote processes. To demonstrate this idea, we proposed two implementations: using a client I/O thread and using MPI remote memory access utility.
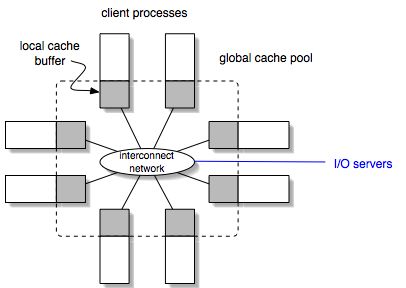
Figure
2. In our caching sub-system, the application processes form a
single client. A global cache pool comprises the cache buffers from all
the processes. Caching is performed by collaborating the client
processes
Last modified on Mar. 30, 2005
Please send comments to
Publications:
- Wei-keng Liao, Alok Choudhary, Kenin Coloma, Lee Ward, Eric Russell, and Neil Pundit. MPI Atomicity and Concurrent Overlapping I/O. A book chapter to appear in High Performance Computing: Paradigm and Infrastructure, John Wiley & Sons Inc. October 2005.
- Wei-keng Liao, Kenin Coloma, Alok Choudhary, and Lee Ward. Cooperative Write-Behind Data Buffering for MPI I/O. In the Proceedings of the 12th European Parallel Virtual Machine and Message Passing Interface Conference (EURO PVM/MPI), Sorrento (Naples), Italy, September 2005.
- Wei-keng Liao, Kenin Coloma, Alok Choudhary, Lee Ward, Eric Russell, and Sonja Tideman. Collective Caching: Application-aware Client-side File Caching. In the Proceedings of the 14th IEEE International Symposium on High Performance Distributed Computing (HPDC-14), pp. 81-90, Research Triangle Park, NC, July 2005.
- Kenin Coloma, Alok Choudhary, Wei-keng Liao, Lee Ward, and Sonja Tideman. DAChe: Direct Access Cache System for Parallel I/O. In the Proceedings of the International Supercomputer Conference, Heidelberg, Germany, June 2005.
- Kenin Coloma, Alok Choudhary, Wei-keng Liao, Lee Ward, Eric Russell, and Neil Pundit. Scalable High-level Caching for Parallel I/O. In the Proceedings of the 18th International Parallel and Distributed Processing Symposium, New Mexico, April 2004.
- Wei-keng Liao, Alok Choudhary, Kenin Coloma, George K. Thiruvathukal, Lee Ward, Eric Russell, and Neil Pundit. Scalable Implementations of MPI Atomicity for Concurrent Overlapping I/O. In the Proceedings of the International Conference on Parallel Processing (ICPP), Kaohsiung, Taiwan, October 2003.
People:
Northwestern University
| P.I. | Alok Choudhary Wei-keng Liao |
| Graduate Students | Avery Ching, Kenin Coloma |
Sandia National Laboratories
Lee Ward
Sponsor:
Sandia National Laboratories
Collaborators:
IBM
Last modified on Mar. 30, 2005
Please send comments to