


~$ ./projects
K-medoids Clustering
The k-medoids methods for modeling clustered data have many desirable properties such as robustness to noise and the ability to use non-numerical values. In this project we developed AGORAS, a novel heuristic algorithm for the k-medoids problem where the algorithmic complexity is driven by, k, the number of clusters, rather than, n, the number of data points. Our algorithm attempts to isolate a sample from each individual cluster within a sequence of uniformly drawn samples taken from the complete data. As a result, computing the k-medoids solution using our method only involves solving k trivial sub-problems of centrality. We evaluate AGORAS experimentally against PAM and CLARANS -- two of the best-known existing algorithms for the k-medoids problem. AGORAS can outperform PAM by up to four orders of magnitude for data sets with less than 10,000 points, and it outperforms CLARANS by two orders of magnitude on a dataset of just 64,000 points. Moreover, we find in some cases that AGORAS also outperforms in terms of cluster quality.An implementation of AGORAS, PAM, and CLARANS, as described in our paper AGORAS: A Fast Algorithm for Estimating Medoids in Large Datasets, is publicly available on GitHub. Click here for the project's code repository.
Building Halo Merger Trees
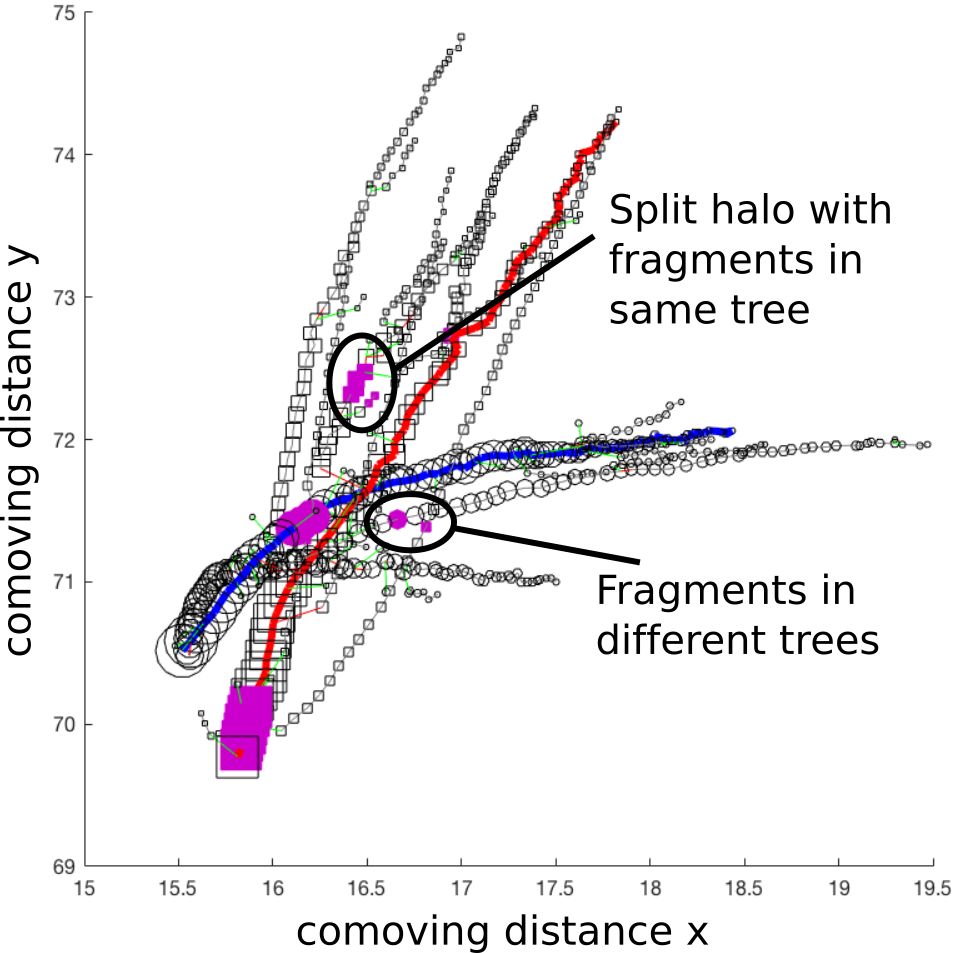 In this work, we present an algorithm for generating merger trees from the standard friends-of-friends (FOF) halos designed to eliminate the adverse effects of temporary mergers -- a primary cause of temporally inconsistent halo properties, and a source of spurious events. Working backwards in time, this algorithm removes splitting halos and inserts their individual components, called ``fragment'' halos, as distinct overdensity particle groups. Our algorithm determines splitting (and merging) halos by computing the intersection cardinality of particles computed over the Cartesian product of halos from adjacent snapshots, using the halo-particle membership function. The particle group for each fragment halo is simply the particle IDs in common with a halo in the next snapshot, with the position and velocity of a fragment halo estimated by tracking the high density core of its progenitor halo. This ``core tracking'' method also allows us to track infall halos after a merger, providing a robust means to place galaxies within halos using empirical and semi-analytic models of galaxy formation.
See our paper, Building Halo Merger Trees from the Q Continuum Simulation for details. This code is not yet publicly available.
In this work, we present an algorithm for generating merger trees from the standard friends-of-friends (FOF) halos designed to eliminate the adverse effects of temporary mergers -- a primary cause of temporally inconsistent halo properties, and a source of spurious events. Working backwards in time, this algorithm removes splitting halos and inserts their individual components, called ``fragment'' halos, as distinct overdensity particle groups. Our algorithm determines splitting (and merging) halos by computing the intersection cardinality of particles computed over the Cartesian product of halos from adjacent snapshots, using the halo-particle membership function. The particle group for each fragment halo is simply the particle IDs in common with a halo in the next snapshot, with the position and velocity of a fragment halo estimated by tracking the high density core of its progenitor halo. This ``core tracking'' method also allows us to track infall halos after a merger, providing a robust means to place galaxies within halos using empirical and semi-analytic models of galaxy formation.
See our paper, Building Halo Merger Trees from the Q Continuum Simulation for details. This code is not yet publicly available.
High Performance Surface Density Field Reconstruction
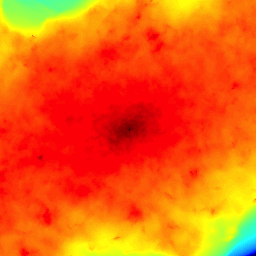 In this project we improve the interpolation accuracy and effiiciency of the Delaunay tessellation field estimator (DTFE) method for surface density field reconstruction. Our algorithm takes advantage of the adaptive triangular mesh for line-of-sight integration. The costly computation of an intermediate 3D grid is completely avoided and only optimally chosen interpolation points are computed, significantly reducing the overall cost of computation.
In this project we improve the interpolation accuracy and effiiciency of the Delaunay tessellation field estimator (DTFE) method for surface density field reconstruction. Our algorithm takes advantage of the adaptive triangular mesh for line-of-sight integration. The costly computation of an intermediate 3D grid is completely avoided and only optimally chosen interpolation points are computed, significantly reducing the overall cost of computation.
Reconstructing a continuous field from a discrete point set is a fundamental operation in scientific data analysis. From a given set of irregularly distributed points in 3D, the task is to create a field defined on a regular grid from some property defined on the points. This work has an application in cosmology and astrophysics for gravitational lensing simulations, where accurate surface density estimation is a critical and costly step, but the techniques developed generalize to any application requiring high-performance grid interpolation with low noise properties. Shown here is a visualization of a typical surface density field computed during a strong lensing study from an N-body particle simulation.
An implementation of the shared memory kernel described in our paper, Parallel DTFE Surface Density Field Reconstruction, is publicly available on GitHub. Click here for the project's code repository.